Episode 2: I am always willing to learn

In Epsode 1 I walked you through getting information from Tfl API ( transport for london ) and using that to start building a graph in Neo4j. Before we go much further in this endeavour, it’s time to look at how we’re approaching the architecture of this code and look at a couple ( there’s more I know ) of items that need looking at.
Lets start with the high level structure of the code which I going to do in layers, rather like a cake. And who doesn’t like Layer Cake or the film of the same name?
Because you have to make this life livable
The top layer of our cake is the Frontend. This is what a user will interact with; maybe it’s a browser, a CLI or something else. Underneath that will be, what I’m calling, an outcomes layer. Outcomes execute the functionality that has been exposed in the Frontend e.g Find a station, get the shortest route between two stations, update station information, update line information etc… This where we will find the business logic. To deliver outcomes, we’ll need to use data and that’s the responsibility of the Data Acccess layer which will be moving data out of TfL API and also to / from Neo4j. To serve the needs of the outcome layer, we’ll need data from Tfl and Neo4j graph database via a series of CRUD type interfaces. Finally, at the bottom, we find our low level communications that is making requests and receiving responses with TfL API and Neo4j.
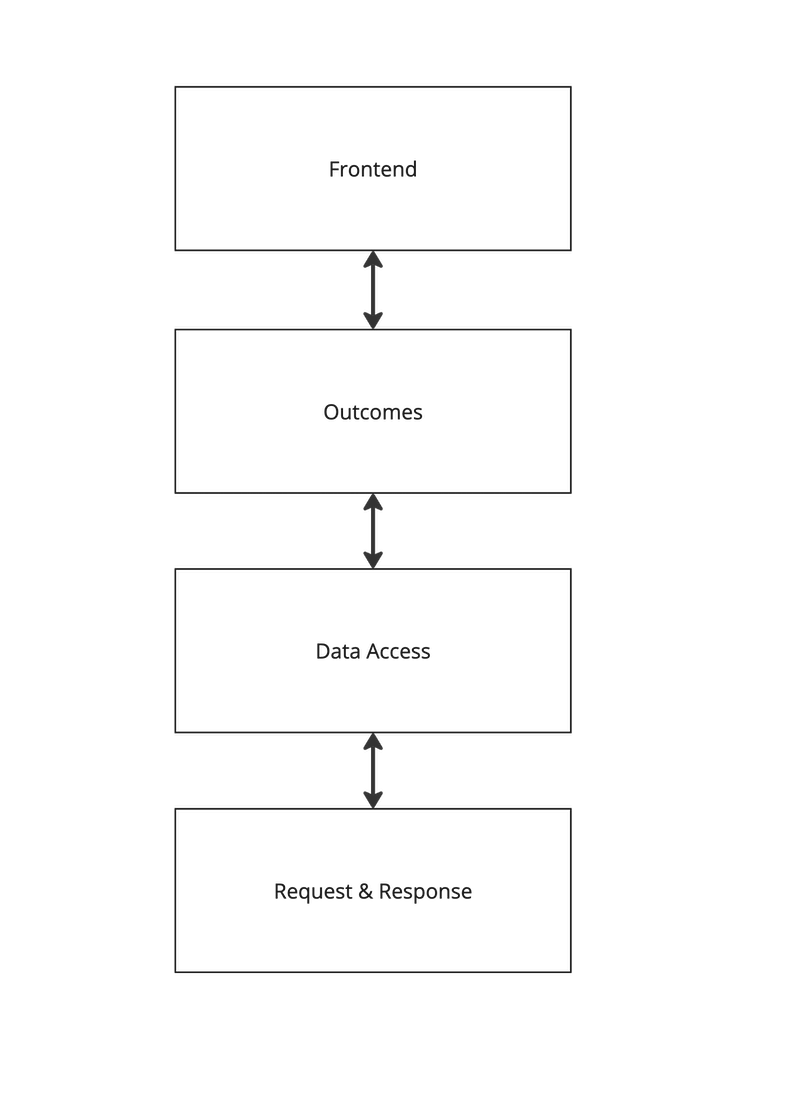
This structure allows us to code ( and test ) each bit seperately. We can mockup the interfaces so that we can work on a higher layer without needing the ones below it to be completed. In summary , its flexible.
Recall I mentioned earlier about a couple of issues? Well some of those are lurking around request / responses with Neo4j and we really should address those before we go any further.
When you’ve got something to teach
Recall this snip of code from Episode 1
for station_entry in tfl_tube_line_stations.json():
# These are the properties to add to our node entry in Neo4j
station_name = station_entry['commonName']
station_id = station_entry['id']
# Detail to connect to our Neo4j database
neo4_uri = 'bolt://127.0.0.1:7687'
neo4j_user = 'neo4j'
neo4j_password = '<YOUR NEO4J PASSWORD>'
# Build the Cypher statement we will use to create the station entry as a node
# We're using MERGE rather than CREATE to avoid creating duplicate stations.
# I've split it across several lines to try and make it easier to read
cypher_statement = 'MERGE ( `' + station_id + '`:Station' + \
' { id:' + '"' + station_id + '"' + \
', name:' + '"' + station_name + '"' + \
'})'
# Connect to Neo4j
neo4jDB_connection = GraphDatabase.driver(neo4_uri, keep_alive=True, auth=(neo4j_user, neo4j_password))
# Send the Cypher statement
neo4j_response = neo4jDB_connection.execute_query(cypher_statement)
# Check the response
print(neo4j_response.summary.metadata)
This loops around the list of stations we obtained from the Tfl API and places them into Neo4j, one at a time. There’s approx 272 tube stations which means we are making the same number of requests to Neo4j.
With a locally installed version of Neo4j e.g Desktop then it’s unlikely you will notice how inefficient this is; there’s no visible slowness and everything speeds along. But try this with a remote database where the connection has many hops and latency is playing a part , then it is a different matter. This is also why you should always try and colocate an application with it’s database.
Because I like to practice what I preach
We can improve the situation ourselves by implementing two of the best practices for performance given in the Neo4j manual for the Python driver.
Use query parameters
When the Cypher statement is put together, I am concatening values together
cypher_statement = 'MERGE ( `' + station_id + '`:Station' + \
' { id:' + '"' + station_id + '"' + \
', name:' + '"' + station_name + '"' + \
'})'
This exposes us to potential Cypher injections ( a bad thing ) and does not allow for leveraging of the database query cache. We can re-write this to use parameters like this
cypher_statement = 'MERGE ( s:Station {id: $station_id, name: $station_name} )'
Which has the added bonus of being more readable.
Batch data creation
Moving to use batch queries will provide the biggest performance improvement. Here we define a Cypher statement that also includes all of the information that we want to place into the database in a single request1.
Our Cypher statement now changes to this
cypher_statement = 'WITH $stations as batch UNWIND batch as station MERGE ( s:Station' {id:station.id, name:station.name})'
$stations will be set to hold a Python dictionary at the time when we use .execute_query method from the Neo4j Python Driver.
The dictionary will look like this [{ “id”:”””, “name”: “”}]
To illustrate, lets look at this example which creates two stations in a single request
# Define the dictionary with the two stations
list_of_stations = [ {"id":"1", "name":"station1"}, {"id":"2", "name":"station2"}]
# Send the Cypher statement
neo4j_response = neo4jDB_connection.execute_query(cypher_statement, stations=list_of_stations)
Ok, lets go apply this to the code from Episode 1 to confirm if we do get a speed up.
Strange highs and strange lows
The dictionary that will contain the list of stations to put into Neo4j needs creating. We’ll loop our way around the response back from TfL API and build the dictionary out like this.
if tfl_tube_line_stations.json():
list_of_stations = []
for station_entry in tfl_tube_line_stations.json():
# These are the properties to add to our node entry in Neo4j
# Which we need in the dictionary that will be sent
# with the Cypher statement
station_data = { "id":station_entry['id'], "name":station_entry['commonName'] }
# Add to the list
list_of_stations.append(station_data)
and then by shifting the code that talks to Neo4j back one indent ( love Python and it’s indents ) which takes it out of the loop, we have
if tfl_tube_lines.json():
for entry in tfl_tube_lines.json():
tfl_tube_id = entry['id']
# Include the line as part of the endpoint that we will use to get the stations
path = "/line/" + tfl_tube_id + "/stoppoints"
# Set the full path
full_url = base_url + path
# Prepare our request
tfl_request = Request('GET', full_url, headers=headers).prepare()
# Send the request to Tfl
tfl_tube_line_stations = tfl_session.send(tfl_request)
if tfl_tube_line_stations.json():
list_of_stations = []
for station_entry in tfl_tube_line_stations.json():
# These are the properties to add to our node entry in Neo4j
# Which we need in the dictionary that will be sent
# with the Cypher statement
station_data = { "id":station_entry['id'], "name":station_entry['commonName'] }
# Add to the list
list_of_stations.append(station_data)
print(list_of_stations)
# Now ready to send to Neo4j
# Detail to connect to our Neo4j database
neo4_uri = '<YOUR NEO4J CONNECTION URL>'
neo4j_user = '<YOUR NEO4J USERNAME>'
neo4j_password = '<YOUR NEO4J PASSWORD>'
# Build the Cypher statement we will use to do a batch creation
cypher_statement = 'WITH $stations as batch UNWIND batch as station MERGE ( s:Station {id: station.id, name: station.name})'
# Connect to Neo4j
neo4jDB_connection = GraphDatabase.driver(neo4_uri, keep_alive=True, auth=(neo4j_user, neo4j_password))
# We'll explicitly set the database
neo4jDB_connection.session(database="Neo4j")
# Send the Cypher statement
neo4j_response = neo4jDB_connection.execute_query(cypher_statement, stations=list_of_stations)
# Check the response
print(neo4j_response.summary.metadata)
Success - it’s even quicker now.
Yes, and I’ll make it all worthwhile
The completed code with speed up changes is here:- Episode2
It was a long read this week - thanks for hangin in - and I still have not got to writing the Request & response layer but I’ve learnt something new resulting in a speed up. Turns out the manuals are useful !
Until next time, stay safe - bonus for the name of the band and the song title that has been sprinkled in todays post.
-
If you’re inserting a lot of information, then break this into multiple requests or use neo4j-admin database import command ↩