Build a Neo4j cluster
Most of time having a single copy of Neo4j running is suitable for what I need to do. There are occasions where only a cluster will do and, as it’s not something that happens that often, I’ve written down the steps i follow that results in a 3 member cluster which is front end by a load balancer - HA Proxy.
I’m aware that you also go down the Kubernetes route for this but it seems overkill for a 3 node cluster with static membership.
Of course I could be wrong and I leave that judgement to you, my dear reader.
Pre-reqs
- A Mac
- podman* for the containers
- neo4j enterprise
- haproxy**
- A text editor. nano is my go to but others are available
*Why podman? It works and it’s free ( at the time of writing ) from the restrictions that docker has . The command line is compatible with that of docker .
**The ports on the containers are kept within a dedicated network. HAProxy acts as a proxy, exposing the ports for Neo4j in an expected way i.e as if it is a single copy of Neo4j running. If we didn’t do this and exposed the containers directly , we would have to use different ports. This makes it complex. As a side benefit, we also get load balancing across the containers.
Folder structures
There’s a folder layout to create. This has one folder for each container with all of the folders under a single parent, neo4j-cluster, which itself will be in the Home folder. If you want another location, thats fine but remember to adjust other references to these in each step.
To create the folders in the home folder, run these commands at the command prompt ( use of -p will create the entire paths in one go and save a bit of key pressing )
mkdir -p ~/neo4j-cluster/node01/conf;mkdir -p ~/neo4j-cluster/node01/data;mkdir -p ~/neo4j-cluster/node01/logs
mkdir -p ~/neo4j-cluster/node02/conf;mkdir -p ~/neo4j-cluster/node02/data;mkdir -p ~/neo4j-cluster/node02/logs
mkdir -p ~/neo4j-cluster/node03/conf;mkdir -p ~/neo4j-cluster/node03/data;mkdir -p ~/neo4j-cluster/node03/logs
mkdir -p ~/neo4j-cluster/haproxy01
Configuration files
neo4j
Each neo4j cluster member will need it’s own, slightly different, configuration file. The file for node01 will act as the template.
Using a text editor, open neo4j.conf file and make these changes
For Initial DBMS Settings, add this line
initial.dbms.default_primaries_count=3
This will make sure any newly created DB will be copied across all three members of this cluster. See https://neo4j.com/docs/operations-manual/current/clustering/databases/
In network connector section, add this line
server.default_advertised_address=node01.dns.podman
In the cluster section, replace the content with these lines
#*****************************************************************
# Cluster Configuration
#*****************************************************************
# Uncomment and specify these lines for running Neo4j in a cluster.
# See the cluster documentation at https://neo4j.com/docs/ for details.
# A comma-separated list of endpoints which a server should contact in order to discover other cluster members. It must
# be in the host:port format. For each machine in the cluster, the address will usually be the public ip address of
# that machine. The port will be the value used in the setting "server.discovery.advertised_address" of that server.
dbms.cluster.discovery.endpoints=node01.dns.podman:5000,node02.dns.podman:5000,node03.dns.podman:5000
dbms.cluster.discovery.log_level=DEBUG
dbms.cluster.discovery.resolver_type=LIST
# Host and port to bind the cluster member discovery management communication.
# This is the setting to add to the collection of addresses in dbms.cluster.discovery.endpoints.
server.discovery.listen_address=:5000
server.discovery.advertised_address=:5000
# Network interface and port for the transaction shipping server to listen on.
# Please note that it is also possible to run the backup client against this port so always limit access to it via the
# firewall and configure an ssl policy.
server.cluster.listen_address=:6000
server.cluster.advertised_address=:6000
# Network interface and port for the RAFT server to listen on.
server.cluster.raft.listen_address=:7000
server.cluster.raft.advertised_address=:7000
# Network interface and port for server-side routing within the cluster. This allows requests to be forwarded
# from one cluster member to another, if the requests can't be satisfied by the first member (e.g. write requests
# received by a non-leader).
server.routing.listen_address=:7688
server.routing.advertised_address=:7688
# List a set of names for groups to which this server should belong. This
# is a comma-separated list and names should only use alphanumericals
# and underscore. This can be used to identify groups of servers in the
# configuration for load balancing and replication policies.
#
# The main intention for this is to group servers, but it is possible to specify
# a unique identifier here as well which might be useful for troubleshooting
# or other special purposes.
#server.groups=
Save this file as neo4j.conf in ~/neo4j-cluster/node01/conf
Then change
server.default_advertised_address=node01.dns.podman
to
server.default_advertised_address=node02.dns.podman
Save this file as neo4j.conf in ~/neo4j-cluster/node02/conf
Finally do the same for node03 by changing
server.default_advertised_address=node02.dns.podman
to
server.default_advertised_address=node03.dns.podman
Save this file as neo4j.conf in ~/neo4j-cluster/node03/conf
To save time, you can download this zip file that contains each of the neo4j configuration files
Note: You might have noticed these lines
dbms.cluster.discovery.endpoints=node01.dns.podman:5000,node02.dns.podman:5000,node03.dns.podman:5000
dbms.cluster.discovery.resolver_type=LIST
Neo4j documentation says this about this configuration line “In order to join a running cluster, any new member must know the addresses of at least some of the other servers in the cluster. This information is necessary to connect to the servers, run the discovery protocol, and obtain all the information about the cluster.”
Essentially I’ve chosen to supply a fixed lists of cluster members with their FQDNS entries. This is absolutely fine for my purposes as the cluster membership never changes. If you’re not in this scenario, make sure you read up on how cluster members find each other https://neo4j.com/docs/operations-manual/current/clustering/setup/discovery/
haproxy
To replicate the load across our neo4j cluster members, haproxy is setup to use a basic round robin mechanism where each request is passed on in turn. haproxy is also configured to present a single IP address that represents the entire cluster so our client can use that rather than each IP address.
haproxy configuration has been divided into a frontend, where requests come in and are then sent onto the backend, the neo4j servers. You can put place various settings that control the flow from frontend to backend. The following file is rather simple and is just enough for what is needed here
global
master-worker
log stdout format raw local0
# Some default options that are used
defaults load_balancer_defaults
log global
option redispatch
option dontlognull
timeout http-request 30s
timeout connect 10s
timeout client 30s
timeout server 30s
###### Frontend ######
# Frontend is where requests come into haproxy
# Some of the configuration is taken from load_balancer_defaults
# Neo4j load balanced browser access
frontend neo4j_http from load_balancer_defaults
bind :7474
mode http
option httplog
#Capture information about http requests in the log file
http-request capture req.hdr(User-Agent) len 100
http-request capture req.body id 0
default_backend neo4j_http_servers
# Neo4j load balanced bolt access
frontend lb_bolt from load_balancer_defaults
mode tcp
option tcplog
bind :7687
default_backend neo4j_bolt_servers
###### Backend ######
# Backend where haproxy sends requests from the frontend
# haproxy will check each server is there by use of the 'check' option at the end
# of each server line
# Backend neo4j for http . includes browser and http / query api
backend neo4j_http_servers from load_balancer_defaults
mode http
option httplog
balance roundrobin
server http01 node01.dns.podman:7474 check
server http02 node02.dns.podman:7474 check
server http03 node03.dns.podman:7474 check
# Backend load balanced bolt access
backend neo4j_bolt_servers
mode tcp
server bolt01 node01.dns.podman:7687 check
server bolt02 node02.dns.podman:7687 check
server bolt03 node03.dns.podman:7687 check
Save this file in the haproxy folder as haproxy.cfg
Create a network for the cluster members
The containers will use their own network with communications between themselves and the host handled by haproxy. To that end, the network will need to be created.
If this network is already in use, adjust as needed
podman network create --subnet 192.168.99.0/24 neo4jCluster
Run the containers
neo4j
Each neo4j cluster member will be started one by one node01
podman run -dt \
--name=node01 \
--hostname node01.dns.podman \
--volume=$HOME/neo4j-cluster/node01/data:/data \
--volume=$HOME/neo4j-cluster/node01/conf:/conf \
--volume=$HOME/neo4j-cluster/node01/logs:/logs \
--env=NEO4J_ACCEPT_LICENSE_AGREEMENT=yes \
--env NEO4J_AUTH=neo4j/password \
--user="$(id -u):$(id -g)" \
--net neo4jCluster \
neo4j:enterprise
node02
podman run -dt \
--name=node02 \
--hostname node02.dns.podman \
--volume=$HOME/neo4j-cluster/node02/data:/data \
--volume=$HOME/neo4j-cluster/node02/conf:/conf \
--volume=$HOME/neo4j-cluster/node02/logs:/logs \
--env=NEO4J_ACCEPT_LICENSE_AGREEMENT=yes \
--env NEO4J_AUTH=neo4j/password \
--user="$(id -u):$(id -g)" \
--net neo4jCluster \
neo4j:enterprise
node03
podman run -dt \
--name=node03 \
--hostname node03.dns.podman \
--volume=$HOME/neo4j-cluster/node03/data:/data \
--volume=$HOME/neo4j-cluster/node03/conf:/conf \
--volume=$HOME/neo4j-cluster/node03/logs:/logs \
--env=NEO4J_ACCEPT_LICENSE_AGREEMENT=yes \
--env NEO4J_AUTH=neo4j/password \
--user="$(id -u):$(id -g)" \
--net neo4jCluster \
neo4j:enterprise
haproxy
podman run -dt \
--name haproxy01 \
--hostname haproxy01.dns.podman \
--volume=$HOME/neo4j-cluster/haproxy01:/usr/local/etc/haproxy:rw \
--net neo4jCluster \
-p 7474:7474 \
-p 7687:7687 \
--user="$(id -u):$(id -g)" \
haproxy:alpine
Cluster checks
Browser
Enter http://localhost:7474 in your browser. You should be shown the browser interface
Set
- Connect URL : bolt://localhost:7687
- Authentication type: Username / password
- Username: neo4j
- Password: password
Select ‘Connect’ to login.
If everything is ok, then you will be logged into neo4j
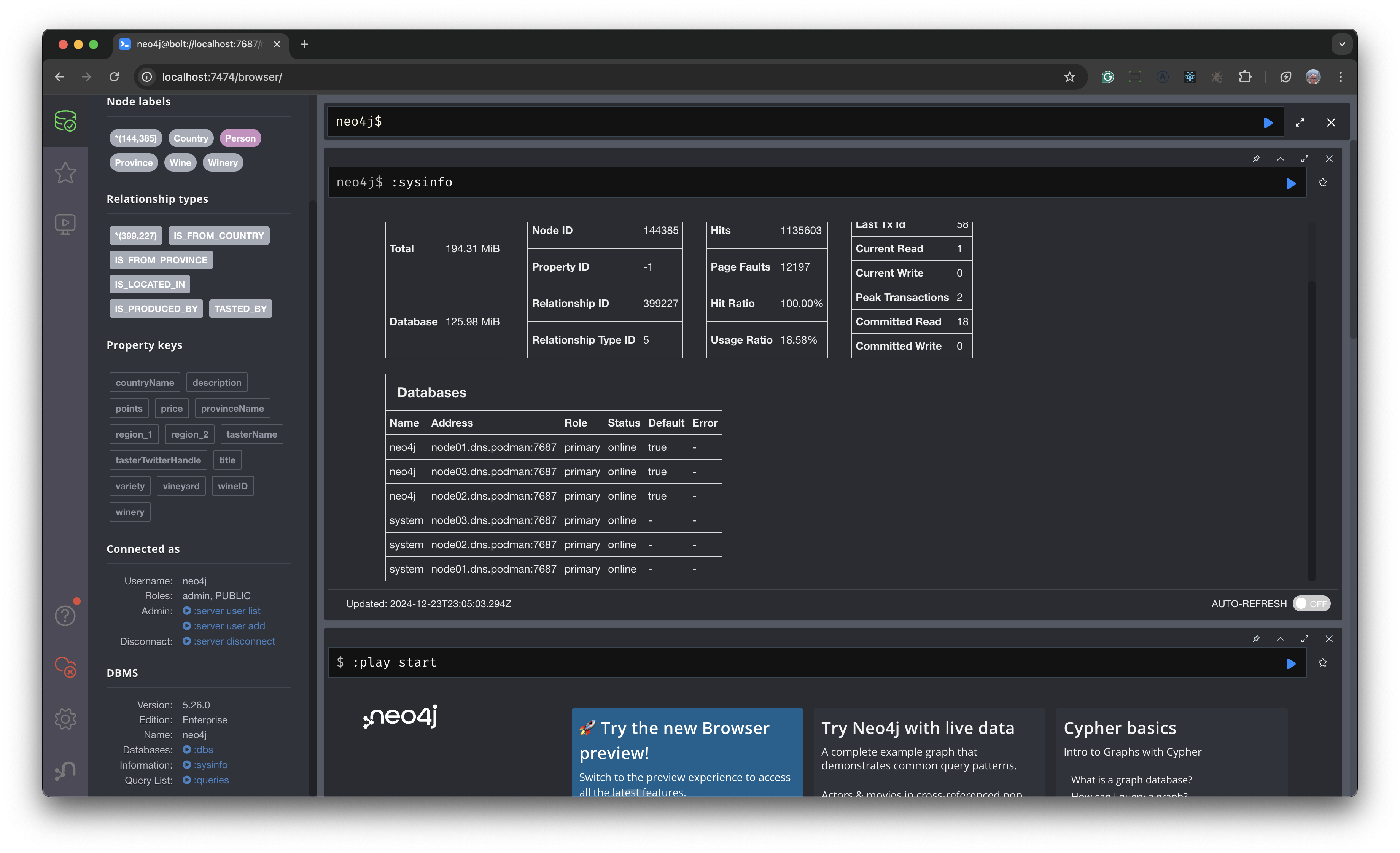
In the browser, type :sysinfo In Databases, you should see all three containers listed as shown in the screenshot below
Query API
To test the Query API, enter this curl command at the command line which will return information about the neo4j user
curl --location 'http://localhost:7474/db/neo4j/query/v2' \
--header 'Content-Type: application/json' \
--data '{ "statement": "SHOW CURRENT USER" }' \
--user neo4j:password
Bolt
Logging from the browser console has tested that bolt communications work. This means that any application using our platform drivers should also work as well.